Joint Out-of-Distribution Filtering and Data Discovery Active Learning
by Sebastian Schmidt, Leonard Schenk, Leo Schwinn and Stephan Günnemann.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025.
Arvix | CVPR | CVPR virtual Event | Code
Abstract:
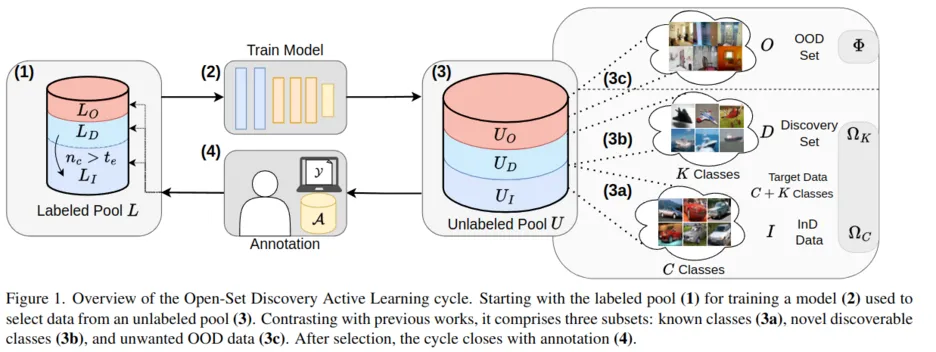
As the data demand for deep learning models increases, active learning (AL) becomes essential to strategically select samples for labeling, which maximizes data efficiency and reduces training costs. Real-world scenarios necessitate the consideration of incomplete data knowledge within AL. Prior works address handling out-of-distribution (OOD) data, while another research direction has focused on category discovery. However, a combined analysis of real-world considerations combining AL with out-of-distribution data and category discovery remains unexplored. To address this gap, we propose Joint Out-of-distibution filtering and data Discovery Active learning (Joda), to uniquely address both challenges simultaneously by filtering out OOD data before selecting candidates for labeling.
In contrast to previous methods, we deeply entangle the training procedure with filter and selection to construct a common feature space that aligns known and novel categories while separating OOD samples. Unlike previous works, Joda is highly efficient and completely omits auxiliary models and training access to the unlabeled pool for filtering or selection.
In extensive experiments on 18 configurations and 3 metrics, Joda consistently achieves the highest accuracy with the best class discovery to OOD filtering balance compared to state-of-the-art competitor approaches.
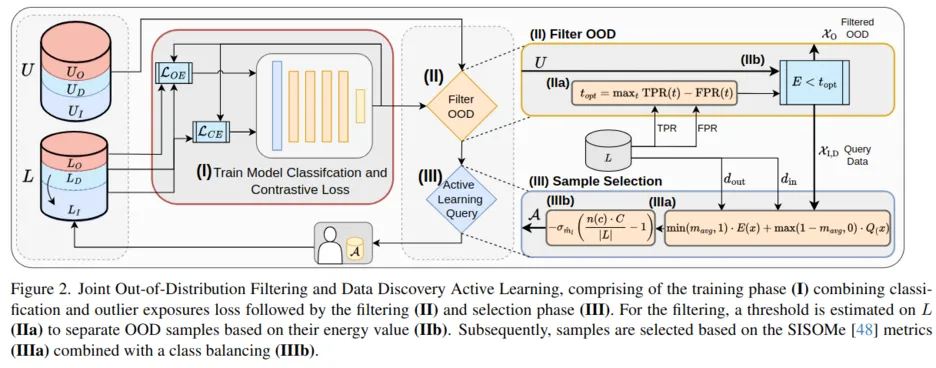
Method:
Joda simplifies the data selection process and addresses the challenges of the introduced Open-set discovery active learning by utilizing a single model that is composed of well-coordinated and interdependent components. In Fig. 2, Joda is outlined, comprising of a training (I), filtering (II), and selection (III) phase. During the training of the task model (I), Joda utilizes InD and unintentionally selected OOD data to separate both distributions’ feature space representation, improving the subsequent OOD filtering (II). As mentioned before, no auxiliary model is trained during this process. After the model is trained, we conduct an OOD filtering (II) leveraging our training scheme and sample selection (III) to identify samples for labeling.